
Бесплатная альтернатива FineReader-у? Открываем распознаватель CuneiForm
12.09.08Мой Компьютер, №05 (509), 16.06.2008
От редакции. «МК» много писал о ПО для распознавания текста. Эту задачу рано или поздно решает, наверное, каждый пользователь. Поэтому мы и уделяли этому вопросу такое внимание. Были у нас материалы и о принципах работы программ-распознавалок, и о конкретной программе — бесспорном лидере в данном направлении программостроения. Мы имеем в виду, конечно же, ABBY Fine Reader, мощнейший и чрезвычайно совершенный инструмент. Однако мы понимаем, что далеко не всем нужен столь серьезный инструмент, а значит, покупка его окажется рентабельной вовсе не для всех. Поэтому предлагаем вашему вниманию утилиту того же назначения, со много более скромными возможностями, существенно менее отлаженную, однако совершенно бесплатную.

Сразу говорю, что на «чужую территорию» я залезать не намерена — только-только окончен в журнале цикл статей о том, как же именно программы распознают тексты. Поэтому просто немного опишу, как использовала ке Cognitive Technologies (разработчики программы. — Прим. ред.), составил порядка 470 человеко-лет» (http://www.cuneiform.ru/news/2007/12_12_2007.html).
 |
|
Рис. 2 |
Установка на двух машинах (WinXP) прошла без проблем — даже непонятно, какие скриншоты в редакцию отправлять, так все соврешенно банально (рис. 2).
Сканер в обоих случаях — HP Scanjet 2400.
 |
|
Рис. 3 |
И в обоих случаях программа для начала заартачилась. То есть при подаче приказа сканировать она вызывала драйвер сканера (какое-то время програ
новую программу — с практической, так сказать, точки зрения.
Сайт программы (http://www.cuneiform.ru) оформлен в стиле «Штирлиц вновь упер из папки сверхсекретный документ» (рис. 1).
 |
|
Рис. 1 |
И очень мне понравился. Программа имеет не очень большой вес — 33 Мб (http://www.cuneiform.ru/downloads/cuneiform.zip), доступна также и с исходными кодами.
На сайте есть форум, который мне помог.
Не могла понять, какой из двух, почему-то было 2 драйвера). Затем исправно сканировала. Рис. 3 — это картинка с драйвера, а вот что в это время, собственно, показывает программа — рис. 4.
 |
|
Рис. 4 |
Потом она не могла вернуть данные обратно в программу. Ошибка описана на форуме — «Проблема в том, что при сканировании документа в самом конце процесса выскакивает ошибка “Ошибка при передаче данных” (http://www.cuneiform.ru/forum/viewtopic.php?t=11) и в теме «FAQ по OCR CuneiForm» (http://www.cuneiform.ru/forum/viewtopic.php?t=18&start=0&postdays=0&postorder=asc&highlight=).
Решила ее, как и написано — в файле Face.INI в параметре TWAIN_TransferMode (он в начале файла) установила параметр в «memory-native». На обеих машинах все заработало аки часики.
Установка на свою машину (WinXP опять же) без сканера тоже произошла без проблем. Правда, при запуске она обратилась к принтеру (а он у меня установлен на другой машине, она же выключена) и заругалась по этому поводу. Когда я нажала ОК, она больше не сердилась.
Українська мова в списке языков, возможных для распознания, присутствует. Кроме русского языка есть еще вариант русско-английский.
А вот выбрать несколько языков одновременно (например, русский, английский и украинский вместе) — увы, не нашла такой возможности. Англо-украинского варианта очень не хватало. Интерфейс на русском, других нет. Хелп на русском.
Скормила сканеру в порядке эксперимента кучу старых документов. Пользовала разрешение 200 (стоит по умолчанию) и 600. При попытке поставить разрешение 1200 компьютер начал ныть, что ему не хватает оперативки, и не закро-о-оете ли вы какую-нибудь програ-а-амму… 1200 решила не трогать.
Самые большие проблемы — с плохонькой матричной распечаткой. Древний принтер измывался над бумагой как хотел. Программа в отсканированной распечатке ничего не поняла — ни в режиме 200, ни в режиме 600.
 |
|
Рис. 5 |
Есть спецрежим — «матричный принтер», нужно поставить птицу в «Параметрах», на вкладке «Разметка и распознавание» (рис. 5).
Такой режим действительно помогает на не очень убитых распечатках; хорошую же распечатку (у меня она была еще и жирная) ест нормально, можно только мелко попридираться.
Хорошо кушает таблицы — даже со сложной структурой.
Объединенные ячейки в кругу нормальных воспринимает спокойно. Причем есть такая закономерность. Если таблица «мелкая» (много столбцов и строчек, все это запихнуто в один лист), то улучшение разрешения ведет к улучшению распознавания. Примерно так же реагирует на таблицу со сложной шапкой, где есть вертикальные строчки заголовков (рис. 6): больше разрешение — лучше результат; на 200 программа вообще растерялась, зато на 600 все было просто идеально.
|
Рис. 6 |
Но если «крупной» таблице с огромными ячейками велеть распознаваться в большом разрешении — то программа «теряет таблицу», т.е. не воспринимает распознаваемое как таблицу.
 |
|
Рис. 7 |
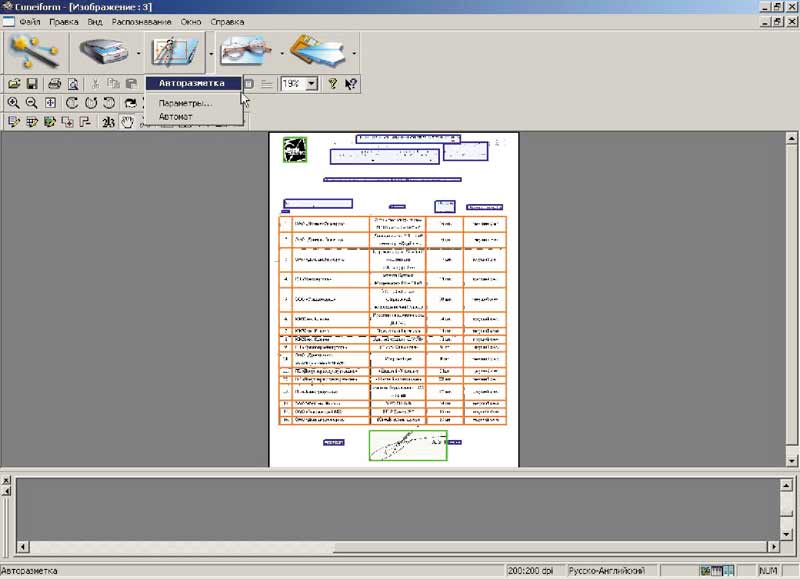
Ручная разметка текста (она чаще всего мне нужна в таблицах) возможна — но только после авторазметки (рис. 7).
Еле нашла.
Рукописных текстов не распознает. И не должен бы, но ведь была надежда…
Есть еще нюанс — уже не программы, а сканера. Может, кому пригодится? Когда приказываешь сканировать, он обязательно делает предварительный проход. И порой на «обратной дороге» сканирующей головки почему-то перекашивает лист — понятно, не сам лист, а его изображение. Если задать сканирование в этот момент, то он и итоговую картинку выдаст кривой. Для борьбы с перекосом нужно просто нажать кнопку «Новое сканирование». Как правило, исправляет.
Самое интересное, что программе в порядке эксперимента была скормлена именно косая распечатка. Распознала! Да еще и лучше, чем «прямую» — там программа запуталась в эффектной «фирменной» шапке листа, где был и текст (инвертный), и картинка. То есть перекособоченные факсы (что их, за уши из аппарата тащат?!) я буду распознавать именно ею — в Fine Reader’e это довольно муторное дело.
Пару раз в трудных случаях распознавания вылетала ошибка «в модуле OCR». Программа не складывалась, по перезапуску распознавания весело приступала к деятельности.
Есть еще некий пакетный режим — когда у вас есть куча уже отсканированных изображений (рис. 8).
Задаются единообразные правила обработки (рис. 9, 10, 11, 12), и распознавалка кушает картинки целой группой (рис. 13).
Рис.8

Рис.9
Рис.10
Рис.11-12
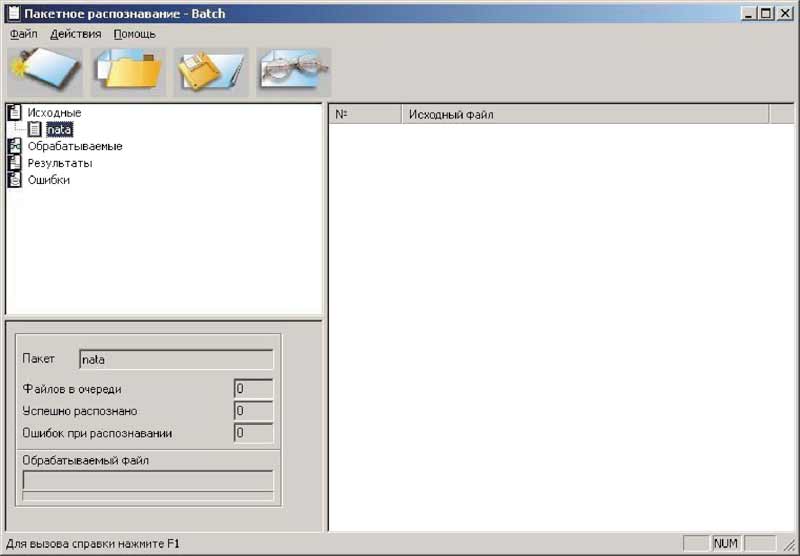
Рис.13
Поскольку у меня каждый документ (ежели уж направляют меня с ним на сканер) — это яркая личность (ох…), и каждый портит нервы по-своему, то мне этот режим вряд ли подойдет. Это не аналог похожего режима в Fine Reader — когда много картинок, сканируемых и распознаваемых поштучно, группируются в пакет. В Cunei Form может быть в данный отдельный момент открыта только одна картинка для распознания; при попытке следующего сканирования спрашивает — а картинку сохранять? а текст? Если картинку не сохранять — про текст не спросит, имейте в виду. Чтобы не потерять результаты работы…
Что можно сказать в целом? В порядке удобства сабж Fine Reader’y явно проигрывает. В плане распознавания — так однозначно сказать трудно. Различия между ними — с точностью до придирки и плохого настроения. Если нет возможности легально владеть Reader’ом — CuneiForm вас, безусловно, выручит. А некоторые неудобства… Что ж, с ними можно мириться, зато чувствуешь себя цивилизованным человеком, а не диким пиратом.
Наталья ЛИТВИНЕНКО
Не пропустите интересное!
Підписывайтесь на наши каналы и читайте анонсы хай-тек новостей, тестов и обзоров в удобном формате!
Обзор смартфона Oppo A6 Pro: амбициозный

Новый смартфон Oppo A6 Pro — телефон среднего уровня с функциональностью смартфонов премиум-класса. Производитель наделил его множеством характеристик, присущих более дорогим телефонам. Но не обошлось и без компромиссов. Как именно сбалансирован Oppo A6 Pro – расскажем в обзоре.
One UI 8.5: новая жизнь старых смартфонов Samsung — что даёт обновление?
One UI 8.5 приносит старым Samsung Galaxy функции, которые ещё недавно были эксклюзивом новых флагманов. Но действительно ли обновление способно сделать Galaxy S22, S23 и S24 ближе к уровню Galaxy S26? Разбираемся, что меняется после установки прошивки.
Logitech Signature Comfort Plus: новые мышь M850 L и комплект MK880

Компания Logitech расширила популярную серию периферии Signature, анонсировав устройства Signature Comfort Plus
В Steam стартовала летняя распродажа: скидки до 90% на тысячи игр

Долгожданная ежегодная летняя распродажа Steam официально стартовала в цифровом сервисе Valve.